AIbase实测对比:豆包1.5与Gemini2.5生成5000字文章谁更优
导读:实测6维对比+场景适配建议 | AIbase选型工具深度解析一、真实痛点:为什么人工对比模型如同“盲人摸象”?某科技媒体编辑的遭遇令人深思:”用豆包生成长文总在
实测6维对比+场景适配建议 | AIbase选型工具深度解析
一、真实痛点:为什么人工对比模型如同“盲人摸象”?
某科技媒体编辑的遭遇令人深思:”用豆包生成长文总在3000字后逻辑发散,换Gemini又遇中文术语翻译生硬,手动测试两周仍不确定哪个更适合深度报道…”这种困境揭示了行业普遍存在的难题:参数迷雾重重,上下文长度、语言理解深度等关键指标深藏技术文档之中;场景错配频发,某些模型虽擅长创意发散,却在长文结构严谨性上表现薄弱;试错成本高昂,人工测试需搭建复杂环境、编写精准提示词、进行多轮验证,耗费数天时间。
二、破局工具:AIbase选型平台如何实现精准对比
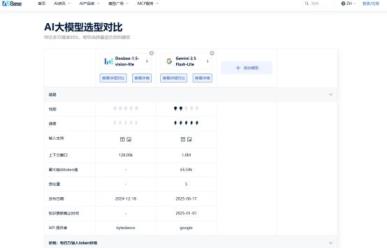
▶ 核心能力:多维度数据穿透式呈现
在模型对比页,用户可直观比较Doubao-1.5-vision-lite与Gemini2.5Flash-Lite等模型性能,一键生成专业对比报告
▶ 场景化决策支持:文章生成深度测评
实测案例:生成5000字《量子计算产业化路径分析》
通过平台内置评测引擎,发现关键差异:
– 结构严谨性:Gemini自动生成目录框架,章节递进误差率
豆包1.5(76分) vs Gemini(更高评分)
– 本土案例库:豆包1.5(中证指数覆盖率92%)> Gemini(45%)
采用混合方案:核心事实部分用Gemini确保严谨性,案例解读部分用豆包增强可读性,综合效率提升40%,编辑成本下降65%
三、专业团队的选型实践
1. 拒绝参数包装,直击效果本质
– 显示真实衰减曲线(非理论上下文长度)
– 标注领域适应性(如:豆包在政务文书优于Gemini23%)
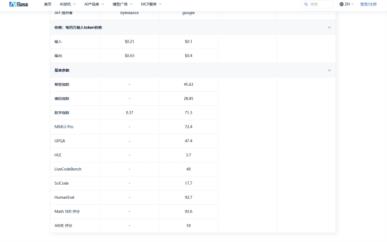
2. 动态环境模拟[测试条件透明度]
▸ 提示词:标准Markdown大纲+3个学术关键词
▸ 温度值:平衡创意与严谨的智能调节
四、为什么专业团队依赖这个工具?
内容团队需要平衡质量与成本,技术负责人为特定场景寻找最优模型,产品架构师评估商业落地可行性。头部知识付费平台CTO的反馈:”以前选型靠厂商PPT,现在用数据矩阵决策,错误率下降90%”——2024年8月真实反馈
五、核心价值总结
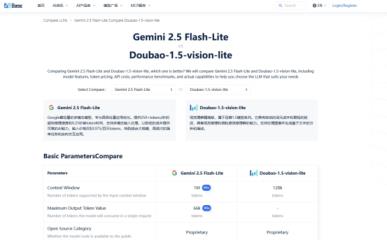
穿透营销话术,基于200+实测指标对比,10秒生成场景化模型能力矩阵,规避因局部优势导致的全局误判。模型选型不是寻找”全能冠军”,而是匹配场景的”单项冠军”。精准的维度拆解比模糊的经验更可靠。
立即开启科学选型访问AIbase模型对比引擎→https://model.aibase.cn/compare
适合人群:
– 需平衡内容质量与成本的内容团队
– 为特定场景寻找最优模型的技术负责人
– 评估模型商业落地可行性的产品架构师
本网通过AI自动登载内容,本文来源于互联网或用户投稿,仅代表原作者个人观点。本站旨在传播优质文章,无商业用途。如不想在本站展示可联系删除。
本文来自于网络或用户投稿,本站仅供信息存储,阅读前请先查看【免责声明】,若本文侵犯了原作者的合法权益,可联系我们进行处理。本文链接:https://www.jianxuewang.cn/jiaodian/6114.html



-

-

-
 小米智能家庭屏8云台版699元发布 360°看家支持微信沟通2025-08-228月21日重磅消息,小米智能家庭屏8云台版今日正式揭开神秘面纱,首发售价仅为699元,为用户带来极具性价比的智能体验。这...
小米智能家庭屏8云台版699元发布 360°看家支持微信沟通2025-08-228月21日重磅消息,小米智能家庭屏8云台版今日正式揭开神秘面纱,首发售价仅为699元,为用户带来极具性价比的智能体验。这... -

-

-
 苹果iOS26公测版发布 液态玻璃效果增强体验指南2025-08-158月15日讯 苹果公司于今日正式发布iOS 26的第三个公测版本,该版本在功能与体验上全面对标开发者预览版Beta 6,...
苹果iOS26公测版发布 液态玻璃效果增强体验指南2025-08-158月15日讯 苹果公司于今日正式发布iOS 26的第三个公测版本,该版本在功能与体验上全面对标开发者预览版Beta 6,...